Lidhja kurioze e Ajnshtajnit me Oppenheimer dhe roli i tij në bo’mbën at’omike. Mori apo






Çfarë pritet nga AI për vitin 2023
Siç shkroi dikur një autor mjaft i suksesshëm komercialisht, “nata është e errët dhe plot tmerre, dita e ndritshme dhe e bukur dhe plot shpresë”. Është imazh i përshtatshëm për AI, i cili si çdo teknologji ka të mirat dhe të këqijat e veta.
Modele që gjenerojnë art si Difuzion i qëndrueshëmpër shembull, kanë çuar në derdhje të pabesueshme të krijimtarisë, fuqizimit aplikacionet dhe madje modele krejtësisht të reja biznesi. Nga ana tjetër, natyra e tij me burim të hapur i lejon aktorët e këqij ta përdorin atë për të krijuar deepfakes në shkallë – gjatë gjithë kohës artistët protestojnë se është duke përfituar nga puna e tyre.
Çfarë është në kuvertë për AI në 2023? A do të frenojë rregullorja më e keqe e asaj që sjell AI, apo janë hapur dyert? Do të shfaqen forma të reja të fuqishme, transformuese të AI, à la ChatGPTduke ndërprerë industritë që dikur mendoheshin të sigurta nga automatizimi?
 “Nuk mjafton të motivosh një komunitet specialistësh [to create new tech] — që teknologjia të bëhet një pjesë afatgjatë e jetës sonë, ajo duhet ose t’i bëjë dikujt shumë para ose të ketë një ndikim domethënës në jetën e përditshme të publikut të gjerë, “tha Cook. “Kështu që unë parashikoj se do të shohim një shtytje serioze për ta bërë AI gjeneruese të arrijë një nga këto dy gjëra, me sukses të përzier.”
“Nuk mjafton të motivosh një komunitet specialistësh [to create new tech] — që teknologjia të bëhet një pjesë afatgjatë e jetës sonë, ajo duhet ose t’i bëjë dikujt shumë para ose të ketë një ndikim domethënës në jetën e përditshme të publikut të gjerë, “tha Cook. “Kështu që unë parashikoj se do të shohim një shtytje serioze për ta bërë AI gjeneruese të arrijë një nga këto dy gjëra, me sukses të përzier.”
 Shembuj të përpjekjeve të tilla të përqendruara në komunitet përfshijnë modele të mëdha gjuhësore nga EleutherAI dhe BigScience, një përpjekje e mbështetur nga startupi i AI Hugging Face. Stabiliteti AI po financon vetë një sërë komunitetesh, si brezi i përqendruar në muzikë Harmonai dhe OpenBioMLnjë koleksion i lirë i eksperimenteve bioteknike.
Kërkohen ende para dhe ekspertizë për të trajnuar dhe drejtuar modele të sofistikuara të AI, por kompjuteri i decentralizuar mund të sfidojë qendrat tradicionale të të dhënave ndërsa përpjekjet me burim të hapur maturohen.
BigScience ndërmori një hap drejt mundësimit të zhvillimit të decentralizuar me publikimin e fundit të projektit me burim të hapur Petals. Petals i lejon njerëzit të kontribuojnë me fuqinë e tyre llogaritëse, të ngjashme me Folding@home, për të ekzekutuar modele të mëdha të gjuhës AI që normalisht do të kërkonin një GPU ose server të nivelit të lartë.
“Modelet gjeneruese moderne janë llogaritëse të shtrenjta për t’u trajnuar dhe përdorur. Disa vlerësime në fund të zarfit i vendosin shpenzimet ditore të ChatGPT në rreth 3 milionë dollarë,” tha përmes emailit Chandra Bhagavatula, një shkencëtar i lartë kërkimor në Institutin Allen për AI. “Për ta bërë këtë komercialisht të zbatueshme dhe të aksesueshme më gjerësisht, do të jetë e rëndësishme të adresohet kjo.”
Chandra thekson, megjithatë, se laboratorët e mëdhenj do të vazhdojnë të kenë avantazhe konkurruese për sa kohë që metodat dhe të dhënat mbeten të pronarit. Në një shembull të fundit, OpenAI u lëshua Pika-E, një model që mund të gjenerojë objekte 3D me një kërkesë teksti. Por ndërsa OpenAI e kishte modelin me burim të hapur, ai nuk zbuloi burimet e të dhënave të trajnimit të Point-E ose nuk i publikoi ato të dhëna.
Shembuj të përpjekjeve të tilla të përqendruara në komunitet përfshijnë modele të mëdha gjuhësore nga EleutherAI dhe BigScience, një përpjekje e mbështetur nga startupi i AI Hugging Face. Stabiliteti AI po financon vetë një sërë komunitetesh, si brezi i përqendruar në muzikë Harmonai dhe OpenBioMLnjë koleksion i lirë i eksperimenteve bioteknike.
Kërkohen ende para dhe ekspertizë për të trajnuar dhe drejtuar modele të sofistikuara të AI, por kompjuteri i decentralizuar mund të sfidojë qendrat tradicionale të të dhënave ndërsa përpjekjet me burim të hapur maturohen.
BigScience ndërmori një hap drejt mundësimit të zhvillimit të decentralizuar me publikimin e fundit të projektit me burim të hapur Petals. Petals i lejon njerëzit të kontribuojnë me fuqinë e tyre llogaritëse, të ngjashme me Folding@home, për të ekzekutuar modele të mëdha të gjuhës AI që normalisht do të kërkonin një GPU ose server të nivelit të lartë.
“Modelet gjeneruese moderne janë llogaritëse të shtrenjta për t’u trajnuar dhe përdorur. Disa vlerësime në fund të zarfit i vendosin shpenzimet ditore të ChatGPT në rreth 3 milionë dollarë,” tha përmes emailit Chandra Bhagavatula, një shkencëtar i lartë kërkimor në Institutin Allen për AI. “Për ta bërë këtë komercialisht të zbatueshme dhe të aksesueshme më gjerësisht, do të jetë e rëndësishme të adresohet kjo.”
Chandra thekson, megjithatë, se laboratorët e mëdhenj do të vazhdojnë të kenë avantazhe konkurruese për sa kohë që metodat dhe të dhënat mbeten të pronarit. Në një shembull të fundit, OpenAI u lëshua Pika-E, një model që mund të gjenerojë objekte 3D me një kërkesë teksti. Por ndërsa OpenAI e kishte modelin me burim të hapur, ai nuk zbuloi burimet e të dhënave të trajnimit të Point-E ose nuk i publikoi ato të dhëna.
 “Unë mendoj se përpjekjet me burim të hapur dhe përpjekjet për decentralizimin janë absolutisht të vlefshme dhe janë në dobi të një numri më të madh studiuesish, praktikuesish dhe përdoruesish,” tha Chandra. “Megjithatë, pavarësisht se janë me burim të hapur, modelet më të mira janë ende të paarritshme për një numër të madh studiuesish dhe praktikuesish për shkak të kufizimeve të tyre të burimeve.”
“Unë mendoj se përpjekjet me burim të hapur dhe përpjekjet për decentralizimin janë absolutisht të vlefshme dhe janë në dobi të një numri më të madh studiuesish, praktikuesish dhe përdoruesish,” tha Chandra. “Megjithatë, pavarësisht se janë me burim të hapur, modelet më të mira janë ende të paarritshme për një numër të madh studiuesish dhe praktikuesish për shkak të kufizimeve të tyre të burimeve.”
 Jashtë kompanive vetëdrejtuese Cruise, Wayve dhe WeRide dhe firmës së robotikës MegaRobo, firmat më të mira të AI për sa i përket parave të mbledhura këtë vit ishin të bazuara në softuer, sipas Crunchbase. Përmbajtja katrore cila shet një shërbim që ofron rekomandime të drejtuara nga AI për përmbajtjen e internetit, mbylli një raund prej 600 milionë dollarësh në korrik. Unifore cila shet softuer për “analitikë bisede” (mendoni matjet e qendrës së thirrjeve) dhe asistentë bisedash, zbarkoi 400 milionë dollarë në shkurt. Ndërkohë, Pika më e lartëplatforma e të cilit e fuqizuar nga AI u ofron përfaqësuesve të shitjeve dhe tregtarëve rekomandime në kohë reale dhe të drejtuara nga të dhënat, kapur 248 milionë dollarë në janar.
Investitorët mund të ndjekin baste më të sigurta si automatizimi i analizave të ankesave të klientëve ose gjenerimi i rezultateve të shitjeve, edhe nëse këto nuk janë aq “seksi” sa AI gjeneruese. Kjo nuk do të thotë se nuk do të ketë investime të mëdha që të tërheqin vëmendjen, por ato do të rezervohen për lojtarët me ndikim.
Jashtë kompanive vetëdrejtuese Cruise, Wayve dhe WeRide dhe firmës së robotikës MegaRobo, firmat më të mira të AI për sa i përket parave të mbledhura këtë vit ishin të bazuara në softuer, sipas Crunchbase. Përmbajtja katrore cila shet një shërbim që ofron rekomandime të drejtuara nga AI për përmbajtjen e internetit, mbylli një raund prej 600 milionë dollarësh në korrik. Unifore cila shet softuer për “analitikë bisede” (mendoni matjet e qendrës së thirrjeve) dhe asistentë bisedash, zbarkoi 400 milionë dollarë në shkurt. Ndërkohë, Pika më e lartëplatforma e të cilit e fuqizuar nga AI u ofron përfaqësuesve të shitjeve dhe tregtarëve rekomandime në kohë reale dhe të drejtuara nga të dhënat, kapur 248 milionë dollarë në janar.
Investitorët mund të ndjekin baste më të sigurta si automatizimi i analizave të ankesave të klientëve ose gjenerimi i rezultateve të shitjeve, edhe nëse këto nuk janë aq “seksi” sa AI gjeneruese. Kjo nuk do të thotë se nuk do të ketë investime të mëdha që të tërheqin vëmendjen, por ato do të rezervohen për lojtarët me ndikim.
Prisni më shumë aplikacione (problematike) të AI që gjenerojnë art
Me suksesin e Lensa, aplikacioni selfie i fuqizuar nga AI nga Prisma Labs që u bë viral, mund të prisni shumë aplikacione me-too në këto linja. Dhe prisni që ata gjithashtu të jenë në gjendje të mashtrohen duke krijuar imazhe NSFWdhe te seksualizojnë dhe ndryshojnë në mënyrë disproporcionale pamjen e femrave. Maximilian Gahntz, një studiues i lartë i politikave në Fondacionin Mozilla, tha se ai priste që integrimi i AI gjeneruese në teknologjinë e konsumatorit do të përforcojë efektet e sistemeve të tilla, si të mirat ashtu edhe të këqijat. Stable Diffusion, për shembull, u ushqye me miliarda imazhe nga interneti derisa “mësoi” të lidhte fjalë dhe koncepte të caktuara me imazhe të caktuara. Modelet që gjenerojnë tekst zakonisht janë mashtruar lehtësisht për të përkrahur pikëpamje fyese ose për të prodhuar përmbajtje mashtruese. Mike Cook, një anëtar i grupit të hapur kërkimor Knives and Paintbrushes, pajtohet me Gahntz se inteligjenca artificiale gjeneruese do të vazhdojë të jetë një forcë e madhe – dhe problematike – për ndryshim. Por ai mendon se viti 2023 duhet të jetë viti që AI gjeneruese “më në fund i vendos paratë e saj aty ku është”.
Prompt nga TechCrunch, model nga Stability AI, i krijuar në mjetin falas Dream Studio.
Artistët udhëheqin përpjekjet për të hequr dorë nga grupet e të dhënave
DeviantArt liruar një gjenerator arti i AI i ndërtuar mbi Stable Diffusion dhe i akorduar mirë në vepra arti nga komuniteti DeviantArt. Gjeneratori i artit u prit me një mosmiratim të madh nga banorët e vjetër të DeviantArt, të cilët kritikuan mungesën e transparencës së platformës në përdorimin e artit të tyre të ngarkuar për të trajnuar sistemin. Krijuesit e sistemeve më të njohura – OpenAI dhe Stability AI – thonë se ata kanë ndërmarrë hapa për të kufizuar sasinë e përmbajtjes së dëmshme që prodhojnë sistemet e tyre. Por, duke gjykuar nga shumë prej brezave në rrjetet sociale, është e qartë se ka punë për të bërë. “Grupet e të dhënave kërkojnë kurim aktiv për të adresuar këto probleme dhe duhet t’i nënshtrohen një shqyrtimi të konsiderueshëm, duke përfshirë nga komunitetet që priren të marrin fundin e shkurtër të shkopit,” tha Gahntz, duke e krahasuar procesin me polemikat e vazhdueshme mbi moderimin e përmbajtjes në mediat sociale. Stabiliteti AI, i cili po financon kryesisht zhvillimin e Stable Diffusion, kohët e fundit iu përkul presionit të publikut, duke sinjalizuar se do t’i lejonte artistët të tërhiqeshin nga grupi i të dhënave të përdorura për të trajnuar modelin e gjeneratës së ardhshme të Stable Diffusion. Nëpërmjet faqes së internetit HaveIBeenTrained.com, mbajtësit e të drejtave do të jenë në gjendje të kërkojnë përjashtime përpara se të fillojë trajnimi pas disa javësh. OpenAI nuk ofron një mekanizëm të tillë përjashtimi, në vend të kësaj preferon të bashkëpunojë me organizata si Shutterstock për të licencuar pjesë të galerive të tyre të imazheve. Por duke pasur parasysh ligjore dhe me erërat e paqarta të publicitetit me të cilat përballet së bashku me Stabilitetin AI, ka të ngjarë vetëm një çështje kohe para se të ndjekë shembullin. Gjykatat përfundimisht mund ta detyrojnë dorën e saj. Në SHBA, Microsoft, GitHub dhe OpenAI janë duke qenë i paditur në një padi kolektive që i akuzon ata për shkelje të ligjit për të drejtën e autorit duke lejuar Copilot, shërbimin e GitHub që sugjeron në mënyrë inteligjente linja kodi, të regurgitojë seksione të kodit të licencuar pa dhënë kredi. Ndoshta duke parashikuar sfidën ligjore, GitHub së fundi shtoi cilësimet për të parandaluar shfaqjen e kodit publik në sugjerimet e Copilot dhe planifikon të prezantojë një veçori që do t’i referohet burimit të sugjerimeve të kodit. Por ato janë masa të papërsosura. Në të paktën një shembullcilësimi i filtrit bëri që Copilot të lëshonte copa të mëdha kodi me të drejtë autori, duke përfshirë të gjithë tekstin e atribuimit dhe licencës. Pritet që kritikat të rriten në vitin e ardhshëm, veçanërisht pasi Britania e Madhe mendon mbi rregullat që do të hiqnin kërkesën që sistemet e trajnuara përmes të dhënave publike të përdoren në mënyrë rigoroze jo-komerciale.Përpjekjet me burim të hapur dhe të decentralizuar do të vazhdojnë të rriten
2022 pa një pjesë të vogël të kompanive të AI që dominojnë skenën, kryesisht OpenAI dhe Stability AI. Por lavjerrësi mund të lëvizë përsëri drejt burimit të hapur në vitin 2023, pasi aftësia për të ndërtuar sisteme të reja lëviz përtej “laboratorëve të inteligjencës artificiale të pasura dhe të fuqishme me burime”, siç e tha Gahntz. Një qasje e komunitetit mund të çojë në më shumë shqyrtim të sistemeve ndërsa ato po ndërtohen dhe vendosen, tha ai: “Nëse modelet janë të hapura dhe nëse grupet e të dhënave janë të hapura, kjo do të mundësojë shumë më tepër kërkime kritike që kanë treguar shumë të meta dhe dëme të lidhura me AI gjeneruese dhe që shpesh ka qenë shumë e vështirë për t’u kryer.”
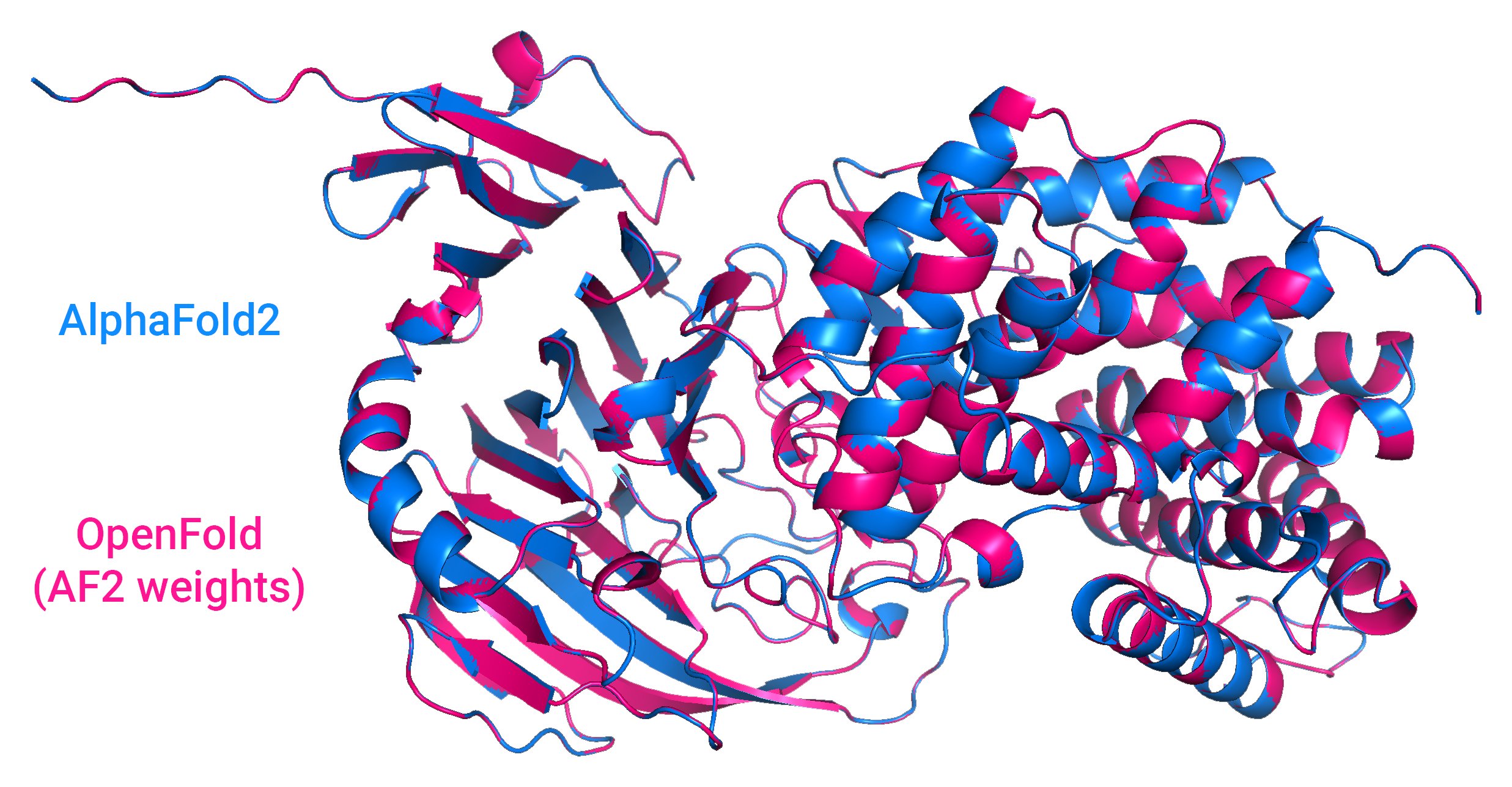
Kreditë e imazhit: Rezultatet nga OpenFold, një sistem AI me burim të hapur që parashikon format e proteinave, krahasuar me AlphaFold2 të DeepMind.
Pika-E gjeneron re pikash. Kreditë e imazhit: OpenAI
Kompanitë e AI shtrëngohen për rregulloret hyrëse
Rregullore si Akti i AI i BE-së mund të ndryshojë mënyrën se si kompanitë zhvillojnë dhe vendosin sistemet e AI duke ecur përpara. Po kështu mund të jenë më shumë përpjekje lokale, si statuti i punësimit të AI në qytetin e Nju Jorkut, i cili kërkon që AI dhe teknologjia e bazuar në algoritme për rekrutimin, punësimin ose promovimin të auditohet për paragjykime përpara se të përdoret. Chandra i sheh këto rregullore si të nevojshme, veçanërisht në dritën e të metave teknike gjithnjë e më të dukshme të AI gjeneruese, si tendenca e tij për të nxjerrë informacione faktikisht të gabuara. “Kjo e bën të vështirë aplikimin e AI gjeneruese për shumë fusha ku gabimet mund të kenë kosto shumë të larta – p.sh. kujdesi shëndetësor. Përveç kësaj, lehtësia e gjenerimit të informacionit të pasaktë krijon sfida rreth dezinformatave dhe dezinformatave,” tha ajo. “[And yet] Sistemet e AI tashmë po marrin vendime të ngarkuara me implikime morale dhe etike.” Viti i ardhshëm do të sjellë vetëm kërcënimin e rregullimit, megjithatë – prisni shumë më tepër grindje mbi rregullat dhe çështjet gjyqësore përpara se dikush të gjobitet ose të akuzohet. Por kompanitë mund të vazhdojnë të kërkojnë pozicione në kategoritë më të favorshme të ligjeve të ardhshme, si kategoritë e rrezikut të Aktit të AI. Rregulli siç është shkruar aktualisht i ndan sistemet e AI në një nga katër kategoritë e rrezikut, secila me kërkesa dhe nivele të ndryshme shqyrtimi. Sistemet në kategorinë e rrezikut më të lartë, AI “me rrezik të lartë” (p.sh. algoritmet e vlerësimit të kredisë, aplikacionet e kirurgjisë robotike), duhet të plotësojnë disa standarde ligjore, etike dhe teknike përpara se të lejohen të hyjnë në tregun evropian. Kategoria më e ulët e rrezikut, AI “minimal ose pa rrezik” (p.sh. filtrat e postës së padëshiruar, video-lojërat e aktivizuara me AI), imponon vetëm detyrime transparence, si ndërgjegjësimi i përdoruesve se ata janë duke ndërvepruar me një sistem AI. Os Keyes, një kandidat për doktoraturë në Universitetin e Uashingtonit, shprehu shqetësimin se kompanitë do të synojnë për nivelin më të ulët të rrezikut në mënyrë që të minimizojnë përgjegjësitë e tyre dhe dukshmërinë ndaj rregullatorëve. “Ky shqetësim mënjanë, [the AI Act] me të vërtetë gjëja më pozitive që shoh në tryezë”, thanë ata. “Nuk kam parë shumë çdo gjë jashtë Kongresit.”Por investimet nuk janë një gjë e sigurt
Gahntz argumenton se, edhe nëse një sistem AI funksionon mjaft mirë për shumicën e njerëzve, por është thellësisht i dëmshëm për disa, ka “ende shumë detyra shtëpie të mbetura” përpara se një kompani ta bëjë atë gjerësisht të disponueshme. “Ekziston edhe një rast biznesi për gjithë këtë. Nëse modeli juaj gjeneron shumë gjëra të ngatërruara, konsumatorët nuk do ta pëlqejnë atë,” shtoi ai. “Por padyshim që kjo ka të bëjë gjithashtu me drejtësinë.” Është e paqartë nëse kompanitë do të binden nga ai argument që do të fillojë vitin e ardhshëm, veçanërisht pasi investitorët duken të etur për të vënë paratë e tyre përtej çdo AI gjeneruese premtuese. Në mes të polemikave të Difuzionit të Qëndrueshëm, Stabiliteti AI i ngritur 101 milion dollarë me një vlerësim mbi 1 miliard dollarë nga mbështetës të shquar duke përfshirë Coatue dhe Lightspeed Venture Partners. OpenAI është tha të vlerësohet në 20 miliardë dollarë sa të hyjë bisedime të avancuara për të mbledhur më shumë fonde nga Microsoft. (Microsoft më parë investuar 1 miliard dollarë në OpenAI në 2019.) Sigurisht, këto mund të jenë përjashtime nga rregulli.
Kreditë e imazhit: Jasper






